

Here is how each works, where each fits, and how most production environments end up using both.
The debate around AI vs rules-based attribute extraction comes up whenever a team inherits a supplier data problem and needs to pick an approach. Both methods extract structured attributes from source documents. They solve the same problem by very different means, and choosing the wrong one adds cost, maintenance burden, or poor extraction quality at scale. Here is how each works, where each fits, and how most production environments end up using both.
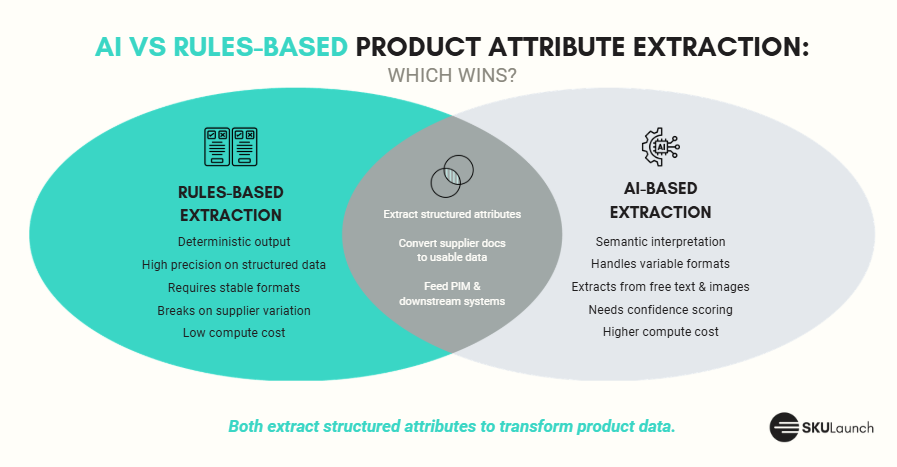
The two approaches
Rules-based extraction works by defining explicit patterns: regular expressions, keyword matchers, positional rules, and field templates that tell the system exactly where to look and what to capture. A rule might say "capture the value in the cell to the right of Voltage:" or "extract any number followed by mm in this column." The rules are deterministic. Given the same input, they produce the same output every time.
AI-based extraction uses language models, vision models, or embeddings to interpret content without predefined patterns. A language model reading a supplier PDF infers that "600V" is a voltage value from context, not because a rule points to it.
Vision models extract values from scanned images or embedded tables with no machine-readable structure. Embeddings map supplier attribute names across different vocabularies to a common schema.
The distinction matters because the two approaches have genuinely different strengths. A full overview of how AI handles this at scale is available in our guide to AI product data extraction.
Where rules-based attribute extraction wins
Rules-based approaches are the right choice when source data is predictable and stable. A supplier who sends a well-formatted spec sheet with the same column headers every week is a rules-based candidate. Pattern rules applied to a 10,000-SKU catalogue with consistent formatting will often outperform a general-purpose model on precision for that specific feed. There is no inference to go wrong, no confidence threshold to tune, and the output is auditable line by line.
Four scenarios where rules-based extraction is the stronger choice:
- Highly structured, stable source data. A supplier whose BMEcat feed has had the same schema for three years suits a rules-based approach. Consistent formatting and predictable field placement are what rules-based systems are built for.
- Completely predictable attribute placement. Spec sheets where a dimension always appears in row 3 of a fixed table benefit from positional rules. The rule reads coordinates rather than context, so layout ambiguity cannot affect the output.
- Low-volume, one-off transformations. Migrating a legacy catalogue of 2,000 SKUs from a clean source file is often faster with rules than deploying a model pipeline. The engineering overhead does not justify the tooling at that scale.
- Regulatory environments requiring deterministic outputs. In medical device distribution or electrical wholesale, some attribute values feed compliance documentation. A rules-based pipeline produces a traceable, repeatable extraction that an auditor can verify step by step.
Where rules-based attribute extraction breaks
Rules break on variation. A distributor managing 400 active suppliers will encounter 400 different interpretations of what a spec sheet looks like. Some use "Rated Voltage," others "V (nom)," others embed the value in a paragraph of marketing copy. A ruleset built for Supplier A fails on Supplier B without new rules being written, tested, and maintained for each format.
Five patterns that expose the limits of rules-based extraction:
1. Inconsistent supplier formats. Each new supplier requires new rules. For a catalogue with 50 active suppliers, that is 50 rulesets to build and maintain. When a supplier updates their template, the rules break silently and incorrect data flows downstream until someone catches it.
2. Natural language descriptions. Product copy that contains attribute values in prose, such as "suitable for circuits up to 240V," does not match positional rules or simple keyword patterns.
3. Multi-product documents. A supplier PDF covering a product family across multiple pages requires a rules engine complex enough that a single layout change breaks hundreds of records at once.
4. Image-embedded attribute values. Values in scanned documents, embedded diagrams, or tables rendered as images are invisible to text-based rules. Regular expressions cannot read a JPEG.
5. New attributes introduced after the rules were built. When a product category requires a new field, every affected supplier template needs updated rules. The maintenance backlog compounds as catalogues grow.
Where AI attribute extraction wins
AI models are well suited to extraction problems where source data is variable and the attribute vocabulary is rich. A language model reading a supplier PDF interprets content semantically: it recognises "IP65" as an ingress protection rating and "RAL 7035" as a colour designation because it has encountered those patterns across a broad training corpus.
Four scenarios where AI-based attribute extraction outperforms rules:
1. Variable supplier formats. A model that generalises across document types handles new supplier formats without new rules. Onboarding a new supplier becomes a validation task rather than a rules-authoring task. For a distributor with 200 suppliers, that difference is measurable in setup time per new feed.
2. Free-text descriptions. Embedding-based extraction reads a paragraph and identifies which words carry attribute values. "This cable is rated for continuous use at temperatures between -15C and 70C" yields two structured values without any pattern being predefined.
3. Context-dependent extraction. The word "rating" means different things in electrical products, food safety certifications, and customer reviews. Language models resolve this from surrounding context; rules do not.
4. Adapting to new attribute types without retraining. When a category standard introduces a new field, an AI-based pipeline can begin extracting it via a prompt update rather than a rules rebuild across every affected supplier template.
For teams dealing specifically with PDF source documents, the guide to extracting product attributes from PDFs at covers the document-format challenges in more detail.
Where AI attribute extraction still needs care
AI extraction is not a hands-off process. Three areas require deliberate engineering to make it production-safe:
1. Confidence scoring and exception review. A model that extracts most attributes correctly still leaves a proportion wrong or missing. Production pipelines need a confidence threshold below which records route to human review. Without this, incorrect values propagate into the PIM silently and surface only when a customer queries a wrong specification.
2. Grounding and verification. Language models can generate plausible-sounding values from vague source material. Grounding extractions against the source document and surfacing the evidence alongside the extracted value makes this class of error visible before it reaches downstream systems.
3. Edge cases in regulated verticals. For attributes that feed compliance documentation or safety data sheets, AI extraction should be treated as a proposal that a deterministic check confirms. The model finds the candidate value; a format and range check verifies it before the record is written.
A practical hybrid approach
Most production attribute extraction pipelines use both methods. The pattern that works at scale across high-volume supplier catalogues:
- Rules for structured fields. For supplier feeds with known, stable schemas, apply rules. High precision, low compute cost, auditable output.
- AI for unstructured fields. Natural language descriptions, scanned documents, inconsistent formats, and new attribute types are where AI extraction earns its place. The model handles semantic interpretation that rules cannot.
- A validation layer combining both. Run rules-based checks as a post-extraction pass: format validation, range checks, and required-field flags. This catches AI inference errors and rules-mismatch failures before records are written to the PIM.
For a wider view of how extraction fits into enrichment, classification, and description generation, the overview of AI product data enrichment covers the full pipeline, while the parent pillar covers how extraction pipelines are architected and scaled.
Evaluation criteria
When assessing which approach fits your situation, or evaluating a vendor's extraction capability, the following criteria are crucial:
- Accuracy at your scale. Ask for benchmark figures on data similar to yours. Rules-based extraction on clean, structured spec sheets from stable supplier feeds will often outperform a general-purpose AI model on that specific data type. AI extraction on variable, unstructured documents will often outperform rules on that type.
- Resilience to format change. How does the pipeline behave when a supplier updates their layout? For rules-based systems, ask how rules updates are managed and how quickly a broken rule is detected. For AI systems, ask whether the model handles variation without retraining, or whether prompt updates suffice.
- Cost per SKU processed. Rules-based processing is computationally cheap per record. AI inference costs scale with volume and model size. At 500,000 SKUs per year, the difference is material. Get unit cost estimates at your expected annual throughput, not per-demo pricing.
- Exception workflow support. Both methods produce records that need human review. A platform that surfaces low-confidence records, shows the source evidence behind each extracted value, and routes exceptions to the right reviewer turns extraction accuracy figures into actual data quality in the PIM.
Key takeaways
- Rules-based extraction is precise, cheap, and auditable on structured, stable source data from consistent supplier feeds.
- It breaks on supplier format variation, natural language content, image-embedded values, and new attribute types added after the rules were built.
- AI extraction handles variable formats, free-text descriptions, and context-dependent interpretation that rules-based systems cannot manage.
- AI pipelines require confidence scoring, source grounding, and exception review workflows to be safe in production.
- The most reliable architecture for high-volume catalogues combines both: rules for structured fields, AI for unstructured, and a validation layer across both.
- When evaluating extraction capability, benchmark against your actual supplier mix and data types, not controlled demo data.
Take the next step
If you're evaluating extraction approaches for your supplier catalogue, SKULaunch applies a hybrid pipeline that routes each document type to rules-based or AI extraction automatically, with confidence scoring and exception review built in. You can see how it handles your source data, including PDFs, spreadsheets, and images, by booking a short demo with us at skulaunch.
See SKULaunch in action
Watch how we handle AI enrichment, supplier onboarding, and catalogue scale in a live 30-minute demo.


.avif)