

Most teams hear ‘AI product data enrichment’ and picture a single ‘magical’ system that can read a supplier PDF and fill the catalogue from end to end
Most teams hear ‘AI product data enrichment’ and picture a single ‘magical’ system that can read a supplier PDF and fill the catalogue from end to end. It doesn’t work like that. Modern enrichment uses several distinct AI techniques, each handling a different part of the problem, each with real limits. This explainer covers what AI actually does inside an enrichment pipeline, where it still needs humans. It also poses the questions worth asking before signing a vendor contract.
What ‘AI’ actually means in product data enrichment
AI is not one technology. In an enrichment context, three different families do most of the work, and they solve different problems. Vendor pitches blur them together. Understanding the components is crucial, because each one fails in a different way.
Language models for extraction and content generation
Large language models read text and write text. In enrichment, they extract structured attributes from unstructured source material: a 40-page datasheet, a supplier email, a manufacturer’s product page. They also generate descriptions, bullet points, and SEO copy from structured input. The same model can do both, but the prompts, guardrails, and evaluation methods are very different. The extraction side overlaps with what most vendors call AI product data extraction.
Computer vision for image-based extraction
Vision models read images. A scanned PDF where the spec table is a picture, not text. A product photo where the model number is printed on the label. A wiring diagram embedded in a catalogue page. Older tools relied on OCR followed by regex, which broke whenever the layout shifted. Modern vision models handle layout variation natively, then hand the cleaned content to a language model for structuring.
Embeddings for classification and matching
Embeddings turn text into numbers that capture meaning. They are how a system decides that ‘cordless impact driver’ and ‘battery-powered impact wrench’ are the same kind of product. Embeddings sit behind classification into a taxonomy like ETIM or UNSPSC, duplicate detection across supplier feeds, and attribute matching when two suppliers use different field names for the same value.
What it is not
None of these models is autonomous. None is always right. None replaces a defined product schema. AI in enrichment is a set of components arranged into a pipeline, with rules, thresholds, and human review built around them. Vendors that claim otherwise are selling a demo, not a working system.
The three things AI is good at in product data enrichment
Three jobs in the enrichment pipeline are now meaningfully better with AI than with rules-based or manual approaches. These are where the technology earns its place.
1. Reading unstructured source material
Traditional extraction tools needed consistent input. One template, one layout, one column order. The moment a supplier sent a PDF with merged cells, or a datasheet built in InDesign, those tools failed and the work fell back to a person manually entering values into a spreadsheet. Modern language and vision models handle layout variation. The same model can read a Word doc from supplier A, a scanned PDF from supplier B, and a marketing page from supplier C, and return the same structured output.
2. Normalising inconsistent formats
One supplier writes ‘100W’. Another writes ‘100 watts’. A third writes ‘Power consumption: 100’. A fourth puts the value in a field called ‘Wattage Input’. Rules-based normalisation needs a mapping for every variant and every new supplier. AI handles this with embeddings and learned conventions. Give it a target schema and the supplier’s source data, and it returns values in your canonical format without bespoke mapping per supplier.
3. Generating consistent content from structured attributes
Once attributes are clean and structured, AI can:
- Generate downstream content faithfully
- Write product descriptions in the tone of voice you specify
- Use bullet points to highlight the attributes that matter to your channel
- Produce meta titles and descriptions for SEO
- Translate content for international stores
This works because the model is generating from a defined set of attributes, not inventing from a category prior.
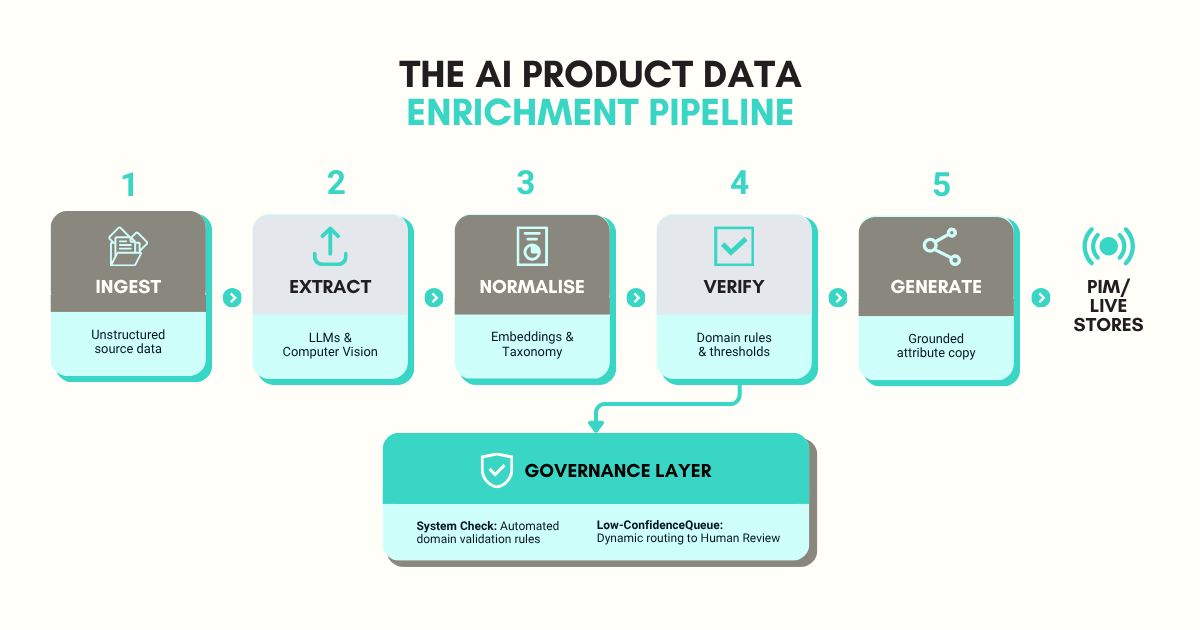
Where AI product data enrichment still needs humans
AI is good at specific tasks inside the pipeline. It isn’t good at the decisions around the pipeline. Three areas still require human judgement, and the vendors that claim otherwise set their customers up for failure.
Schema design and taxonomy definition
AI can populate a schema. It cannot decide what the schema should be. The questions are commercial. That is, which attributes:
- Drive faceted search on your site
- Enable a buyer to compare before deciding
- Are required for legal compliance in your product class
Those choices belong to merchandising, search, and product teams. Until a schema exists, AI has no target towards which it’s enriching.
Confidence thresholds and exception review
Every AI extraction comes with a confidence score. High-confidence extractions pass through. Low-confidence extractions queue for review. The threshold between the two is a business decision. Set it too low and bad data flows through to live storefronts. Set it too high and a person reviews everything, which defeats the point. The right threshold depends on category risk, channel sensitivity, and the cost of an error. Most platforms, including SKULaunch’s enrichment studio, expose this as a configurable workflow rather than a fixed number.
Domain-specific validation
AI doesn’t know that a 5kg engine block weight should not come back as 5g. It doesn’t know that ‘M8’ in a fastener context refers to thread size, not a model number. It doesn’t know that an electrical product missing a CE marking attribute cannot ship to the EU. These are domain rules. Some can be codified into validation logic. The rest still need a reviewer who has in-depth knowledge of the category.
Why grounding matters for AI product data enrichment
Grounding is the difference between an AI system that reports facts and an AI system that invents them. It is the single most important architecture decision in any enrichment vendor’s product, and one of the least asked-about in buyer evaluations.
Hallucination in content generation
Language models generate plausible-sounding output by default. Ask an ungrounded LLM to write a description for a specific drill, and it produces confident, detailed copy with values that may or may not match the real product. The model is doing what it was trained to do: predict likely text. The values it returns are not lookups; they are guesses that happen to appear like lookups.
Generating from prompts versus generating from verified attributes
A grounded system never asks the model to invent. It extracts attributes from source material first, stores them as verified values against the product record, then prompts the model to write copy using only those attributes. The same model produces accurate output because it’s now writing from a known set of facts. The technique is the same. The architecture is different. The accuracy is not comparable.
What to ask vendors about grounding
Three questions cut through marketing language:
- Where do source attributes come from, and is every extracted value traceable back to a source document?
- When the model generates a description, which specific attributes did it use?
- What does the system do when an expected attribute is missing: refuse to generate, fall back to a default, or invent?
Vendors with a serious grounding can answer these without hedging their bets.
Practical questions for evaluating AI product data enrichment
Before any vendor demo, work through this list. The answers separate platforms built for catalogue data from generic AI tools dressed up as enrichment products.
- AI techniques in use: which models (language, vision, embeddings) does the platform use, and where in the pipeline does each one run?
- Grounding architecture: how are extractions tied to source material, and can any generated output be traced back to its source attributes?
- Confidence scoring: how are scores calculated, and can you tune the review threshold per attribute, per category, or per supplier?
- Human review workflow: what does the queue look like for low-confidence outputs, and who can action it?
- Schema and taxonomy support: how are target schemas and standard taxonomies (ETIM, UNSPSC, custom) imported and maintained?
- Destinations: which systems does the platform push enriched data to (Akeneo, Plytix, Shopify, Magento, Mirakl, your PIM)?
- Audit trail: can you see which model or user changed each attribute and when, and thus roll back if needed?
- Multi-language handling: if you sell across geographies, how does the platform handle translation and locale-specific attributes?
A capable product data enrichment platform answers each of these with specifics rather than positioning. A weaker one talks about its AI in the abstract.
Contact SKULaunch
Before evaluating any AI enrichment platform, it is worth knowing how ready your existing product data is to be enriched. SKULaunch offers a product data readiness audit covering schema quality, supplier source material, classification gaps, and integration constraints. The output is a practical roadmap with effort and cost estimates, not a sales pitch. Contact SKULaunch to book your audit.
See SKULaunch in action
Watch how we handle AI enrichment, supplier onboarding, and catalogue scale in a live 30-minute demo.



.avif)